A verification layer for browser agents: Amazon case study
How structured snapshots + Jest-style assertions make small local models reliable.
This post is a technical report on four runs of the same Amazon shopping flow. The purpose is to isolate one claim: reliability comes from verification, not from giving the model more pixels or more parameters.
Sentience is used here as a verification layer: each step is gated by explicit assertions over structured snapshots. This makes it feasible to use small local models as executors, while reserving larger models for planning (reasoning) when needed. No vision models are required for the core loop in the local runs discussed below.
Key findings
| Finding | Evidence (from logs / report) |
|---|---|
| A fully autonomous run can complete with local models when verification gates every step. | Demo 3 re-run: Steps passed: 7/7 and success: True |
| Token efficiency can be engineered by interface design (structure + filtering), not by model choice. | Demo 0 report: estimated ~35,000 → 19,956 tokens (~43% reduction) |
| Verification > intelligence is the practical lesson. | Planner drift is surfaced as explicit FAIL/mismatch rather than silent progress |
Key datapoints:
| Metric | Demo 0 (cloud baseline) | Demo 3 (local autonomy) |
|---|---|---|
| Success | 1/1 run | 7/7 steps (re-run) |
| Duration | ~60,000ms | 405,740ms |
| Tokens | 19,956 (after filtering) | 11,114 |
Task (constant across runs): Amazon → Search “thinkpad” → Click first product → Add to cart → Proceed to checkout
First principles: structure > pixels
Screenshot-based agents use pixels as the control plane. That often fails in predictable ways: ambiguous click targets, undetected navigation failures, and “progress” without state change.
The alternative is to treat the page as a structured snapshot (roles, text, geometry, and a small amount of salience) and then require explicit pass/fail verification after each action. This is the “Jest for agents” idea: a step does not succeed because the model says it did; it succeeds because an assertion over browser state passes.
The “impossible benchmark”
The target configuration is a strong planner paired with a small, local executor, still achieving reliable end-to-end behavior. Concretely: DeepSeek-R1 (planner) + a ~3B-class local executor, with Sentience providing verification gates between steps.
Note on attribution: the run logs included in this post report outcomes (duration/tokens/steps) but do not consistently print model identifiers. Where specific model names are mentioned below, they are explicitly labeled as run configuration.
Why this is a useful benchmark:
- The executor is intentionally “dumb”: it only needs to choose DOM actions (CLICK/TYPE) against a compact representation.
- Reliability comes from the verification layer: each action is followed by snapshot + assertions that gate success and drive bounded retries.
In other words, the point is not that small models are magically capable; it’s that verification makes capability usable.
Setup and dependencies
These demos use the Sentience Python SDK, Playwright for browser control, and local LLMs for planning/execution. The minimal install sequence is straight from the SDK README:
# Install from PyPI
pip install sentienceapi
# Install Playwright browsers (required)
playwright install chromium
# For local LLMs (optional)
pip install transformers torch # For local LLMsVideo artifacts are generated from screenshots; if ffmpeg is available, the run assembles a short summary clip (the logs show creation even when ffmpeg errors occur in some runs).
Architecture: the 3-model stack (planner, executor, verifier)
Sentience separates planning from execution, and inserts verification in the middle:
Planner LLM → JSON Plan (steps + required verification)
↓
AgentRuntime
(snapshot + verify + trace)
↓
Executor LLM (CLICK/TYPE)
↓
AsyncSentienceBrowser + Extension
↓
Trace pipeline → Sentience StudioThe key is the runtime: every action is wrapped in a snapshot + verification cycle that produces pass/fail evidence. Verification is inline runtime gating (it determines whether the step succeeds), not post-hoc analysis.
Clarifying terms used below:
- Planner (reasoning): produces a structured plan (steps + required verifications).
- Executor (action): selects concrete DOM actions (CLICK/TYPE) against the current snapshot.
- Verifier (assertions): evaluates explicit assertions over snapshots and gates step/task success (with deterministic overrides when intent is unambiguous).
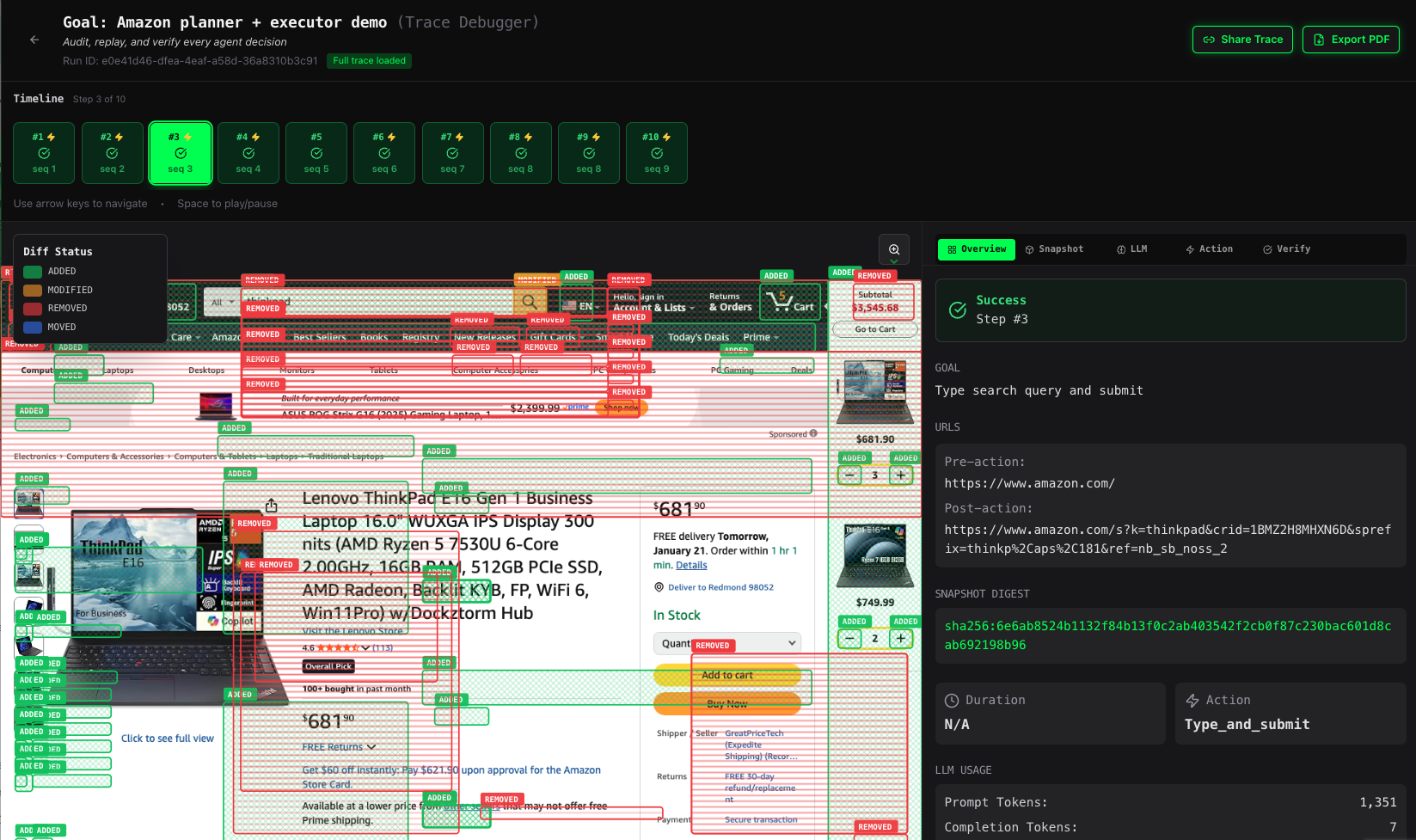
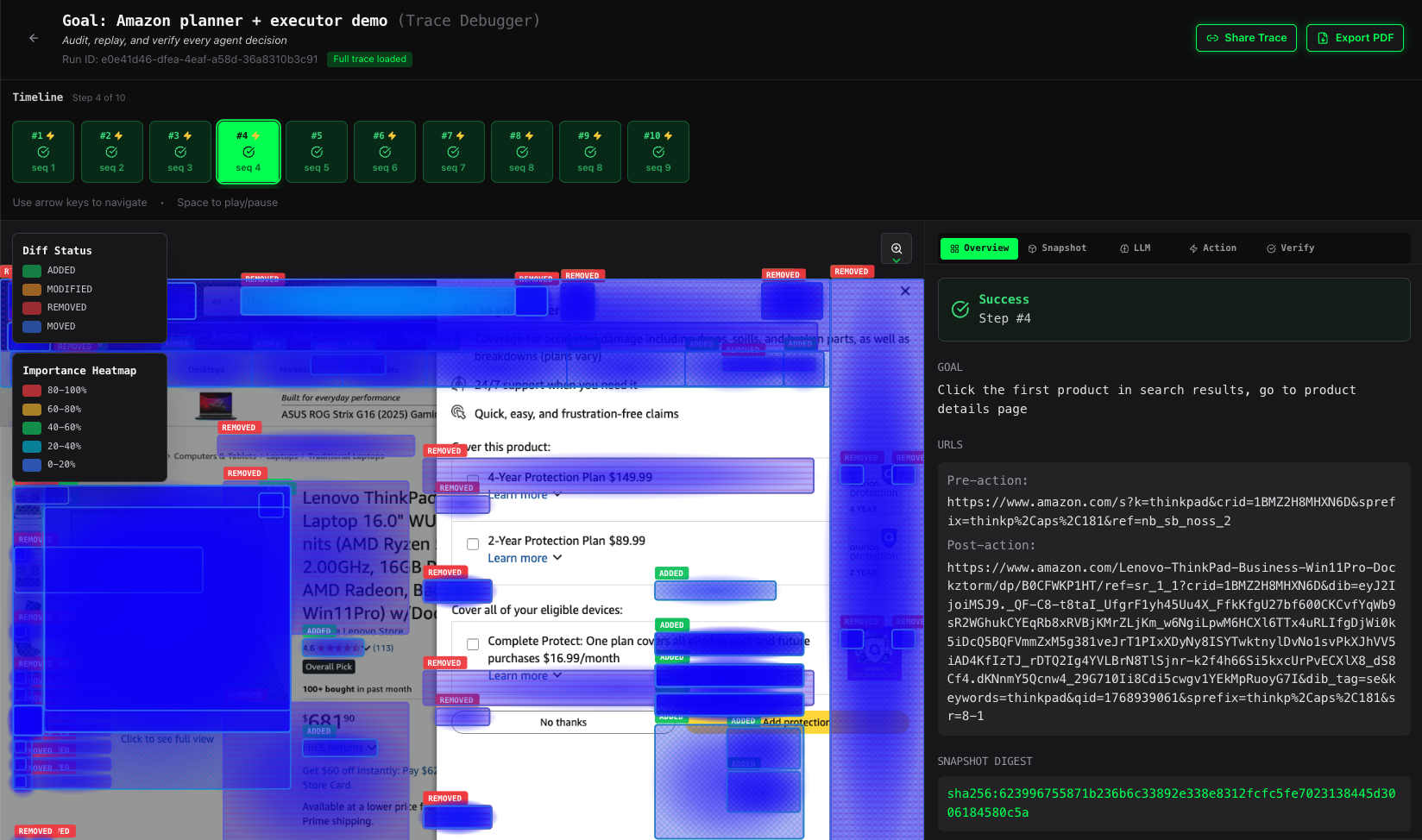
Amazon shopping flow snapshot diff status between 2 steps (shows whether the LLM action succeeded)
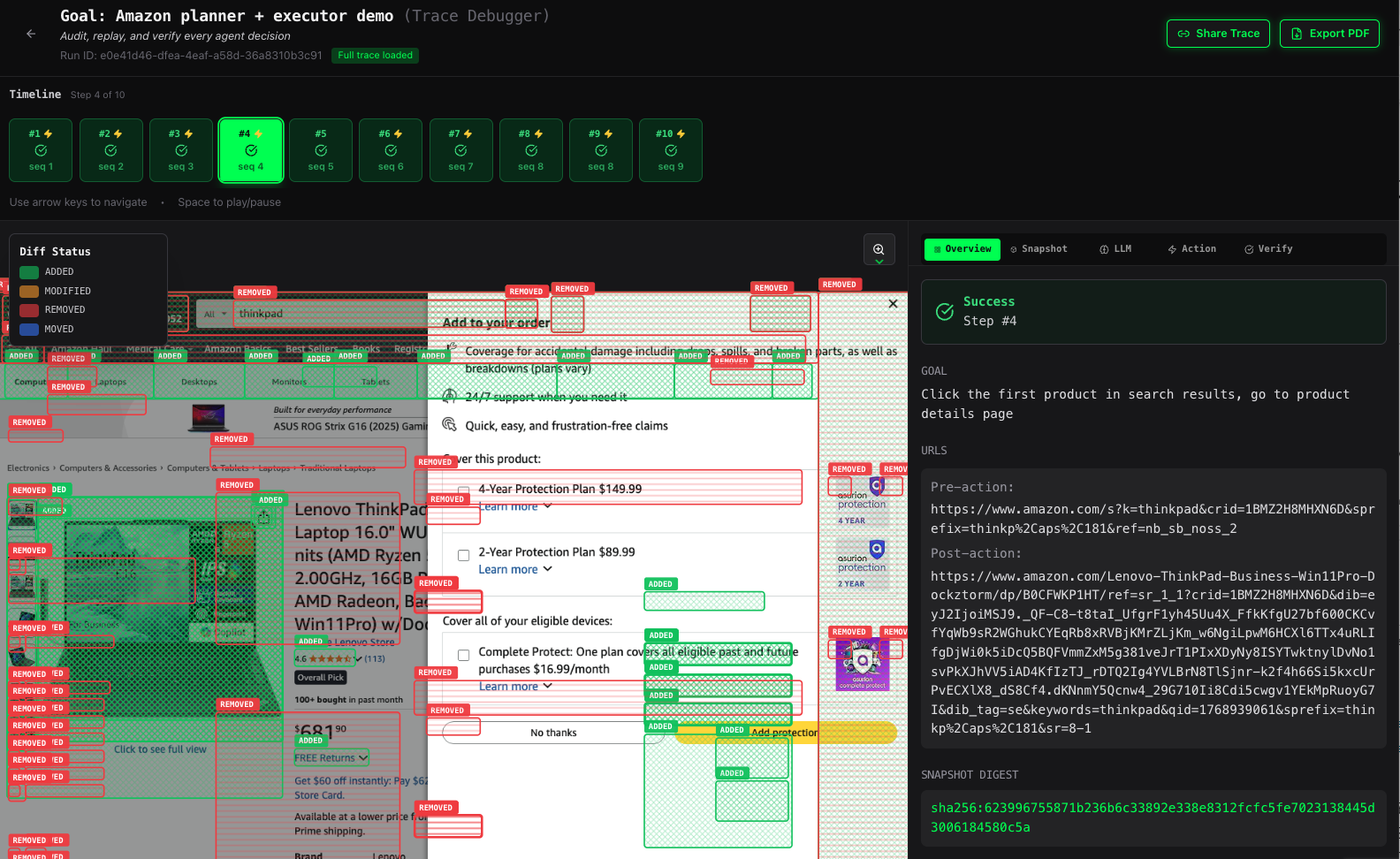
Amazon shopping flow snapshot heatmap by importance of top elements
The verification layer (SDK code you can copy)
At the runtime level, assertions are first-class, recorded as events, and can gate success. From AgentRuntime.assert_():
def assert_(
self,
predicate: Predicate,
label: str,
required: bool = False,
) -> bool:
"""
Evaluate an assertion against current snapshot state.
The assertion result is:
1. Accumulated for inclusion in step_end.data.verify.signals.assertions
2. Emitted as a dedicated 'verification' event for Studio timeline
"""
outcome = predicate(self._ctx())
self._record_outcome(
outcome=outcome,
label=label,
required=required,
kind="assert",
record_in_step=True,
)
if required and not outcome.passed:
self._persist_failure_artifacts(reason=f"assert_failed:{label}")
return outcome.passedTo support async UI, the runtime exposes fluent retry logic:
def check(self, predicate: Predicate, label: str, required: bool = False) -> AssertionHandle:
"""
Create an AssertionHandle for fluent .once() / .eventually() usage.
This does NOT evaluate the predicate immediately.
"""
return AssertionHandle(runtime=self, predicate=predicate, label=label, required=required)Predicates are explicit, composable, and operate over semantic snapshots. For example:
def url_contains(substring: str) -> Predicate:
def _pred(ctx: AssertContext) -> AssertOutcome:
url = ctx.url or ""
ok = substring in url
return AssertOutcome(
passed=ok,
reason="" if ok else f"url does not contain: {substring}",
details={"substring": substring, "url": url[:200]},
)
return _preddef exists(selector: str) -> Predicate:
def _pred(ctx: AssertContext) -> AssertOutcome:
snap = ctx.snapshot
if snap is None:
return AssertOutcome(
passed=False,
reason="no snapshot available",
details={"selector": selector, "reason_code": "no_snapshot"},
)
from .query import query
matches = query(snap, selector)
ok = len(matches) > 0
return AssertOutcome(
passed=ok,
reason="" if ok else f"no elements matched selector: {selector}",
details={
"selector": selector,
"matched": len(matches),
"reason_code": "ok" if ok else "no_match",
},
)
return _predThis is why the system behaves like a test harness: assertions are deterministic, and failures produce artifacts instead of silent drift.
A tiny comparison table (control plane and failure mode)
| Approach | Control Plane | Failure Mode |
|---|---|---|
| Vision agents | Screenshots | Silent retries |
| Raw DOM | HTML text | Hallucinated selectors |
| Sentience | Structured snapshot + assertions | Explicit FAIL with artifacts |
Token efficiency is not a side effect here. The structure-first snapshot plus role filtering reduced prompt volume by ~43% in the cloud LLM baseline (Demo 0), while keeping the same deterministic verification loop.
The four demos (same task, different autonomy)
Demo 3 — Local autonomy (planner + executor) with verification gates
See Code
Inputs
- Planner (reasoning): DeepSeek-R1 family (run configuration; see note above)
- Executor (action): local Qwen family (run configuration; the “impossible benchmark” target is ~3B-class)
- Verifier (assertions): Sentience runtime gates (structured snapshots + explicit assertions + deterministic overrides)
Verification
- Each step is gated by explicit assertions over snapshots (URL predicates, element existence, etc.)
- Deterministic overrides are applied when intent is unambiguous (e.g., drawer dismissal)
Outcome The re-run completed end-to-end:
=== Run Summary ===
success: True
duration_ms: 405740
tokens_total: 11114
Steps passed: 7/7The practical point is not that the executor “understands Amazon.” It selects actions inside a loop that proves outcomes (via assertions) and forces the correct branch when intent is unambiguous (via deterministic overrides).
Demo 3 is the latest result in this case study - the one we care about most (local autonomy with verification). To give the full context, the next sections go back to the earliest baseline (Demo 0) and then walk forward through Demo 1 and Demo 2, showing the evolution: how structure-first snapshots, verification gates, and element filtering made the system cheaper and more reliable before we reached full autonomy.
Demo 0 — Cloud LLM + Sentience SDK (structured JSON)
See Code
Earlier baseline (Dec 2025 report). This run used a cloud model (GLM-4.6) with Sentience’s structured snapshot pipeline. The key contribution was reducing the problem to structured elements and gating each step with verification.
Token reduction from element filtering (as reported):
| Metric | Before | After | Reduction |
|---|---|---|---|
| Prompt tokens (estimated) | ~35,000 | 19,956 | ~43% |
Demo 1 — Human steps + Local Qwen 2.5-3B executor
See Code
Inputs
- Planner: human-authored steps
- Executor: Local Qwen 2.5-3B (run configuration)
- Verifier: Sentience assertions
Outcome This isolates the verification layer and structured snapshot format with a small local executor.
Demo 2 — Local Qwen 2.5-7B planner + Qwen 2.5-3B executor (autonomous)
See Code
Inputs
- Planner: Local Qwen 2.5-7B (run configuration)
- Executor: Qwen 2.5-3B (run configuration)
- Verifier: Sentience assertions + overrides
Verification When the planner’s verification target becomes brittle under UI ambiguity, the runtime surfaces the mismatch via explicit verification failures (rather than silently proceeding).
Context: cross-demo outcome summary. The table below is a compact comparison of the four demos (cloud baseline → human-plan control → autonomous planning → local autonomy), highlighting duration, token usage, and step completion.
| Demo | Planner / Executor | Duration | Tokens | Steps |
|---|---|---|---|---|
| 0 | Cloud LLM (run config) + Sentience SDK | ~60,000ms | 19,956 | 1/1 run |
| 1 | Human plan + Local Qwen 2.5-3B (run config) | 207,569ms | 5,555 | 9/9 steps |
| 2 | Local Qwen 2.5-7B + Qwen 2.5-3B (run config) | 435,446ms | 13,128 | 7/8 steps |
| 3 | DeepSeek-R1 family + local Qwen family (run config) | Run A: 496,863ms / Run B: 405,740ms | 12,922 / 11,114 | 7/8 → 7/7 steps |
What the logs show (concrete evidence)
Deterministic overrides (first product)
The executor can be overruled when the runtime has a safer deterministic choice:
[fallback] first_product_link preselect -> CLICK(1022)
Executor decision: {"action": "click", "id": 884, "raw": "CLICK(884)"}
[override] first_product_link -> CLICK(1022)This is not a model preference. It is an explicit guardrail that preserves the “first result” intent.
Drawer handling (add-on upsell)
When Amazon opens the add-on drawer, the runtime dismisses it deterministically:
[fallback] add_to_cart drawer detected -> CLICK(6926)
Executor decision: {"action": "click", "id": 1214, "raw": "CLICK(1214)"}
[override] add_to_cart -> CLICK(6926)Result:
result: PASS | add_to_cart_verified_after_drawerPlanner drift (brittle selector)
In the autonomous planner run, the verification target briefly drifted into a brittle selector; the runtime still enforces pass/fail deterministically, which is why the mismatch is surfaced rather than glossed over:
"intent": "checkout_button",
"verify": [
{
"predicate": "exists",
"args": [
"data-test-id=nav-x-site-nav-button-checkout"
]
}
]The system caught the mismatch with assertions, but it highlights why verification must be strong before model scale pays off.
Run summaries (from logs)
Demo 0 (Cloud LLM + Sentience SDK; report excerpt):
success: True
duration_ms: ~60000
tokens_total: 19956
notes: token reduction ~43% (estimated ~35,000 → 19,956) via element filteringDemo 1 (Human steps + Qwen 2.5-3B executor):
=== Run Summary ===
success: True
duration_ms: 207569
tokens_total: 5555
Steps passed: 9/9Demo 2 (Qwen 2.5-7B planner + Qwen 2.5-3B executor):
=== Run Summary ===
success: True
duration_ms: 435446
tokens_total: 13128
Steps passed: 7/8Demo 3 Run A (DeepSeek-R1-Distill-Qwen-14B planner + Qwen 2.5-7B executor): (Model identifiers are run configuration; the excerpted logs primarily report outcome metrics.)
=== Run Summary ===
success: True
duration_ms: 496863
tokens_total: 12922
Steps passed: 7/8Demo 3 Re-run:
=== Run Summary ===
success: True
duration_ms: 405740
tokens_total: 11114
Steps passed: 7/7The run also emits a trace upload confirmation:
✅ [Sentience] Trace uploaded successfullySome runs use MLX backends (Apple Silicon). MLX does not expose token usage metrics, so token totals can be directional; plan stability and retry counts are the more reliable signal in those cases.
Observability and artifacts
Each step produces structured traces, snapshots, and artifacts. The run automatically creates a video summary from screenshots:
Creating video from screenshots in .../screenshots/20260120_115426...
Found 7 screenshots
...
✅ Video created: .../demo.mp4
✅ [Sentience] Trace uploaded successfullyThese traces power Sentience Studio: diff_status, evidence, and a timeline of verification events that explain why a step passed or failed.
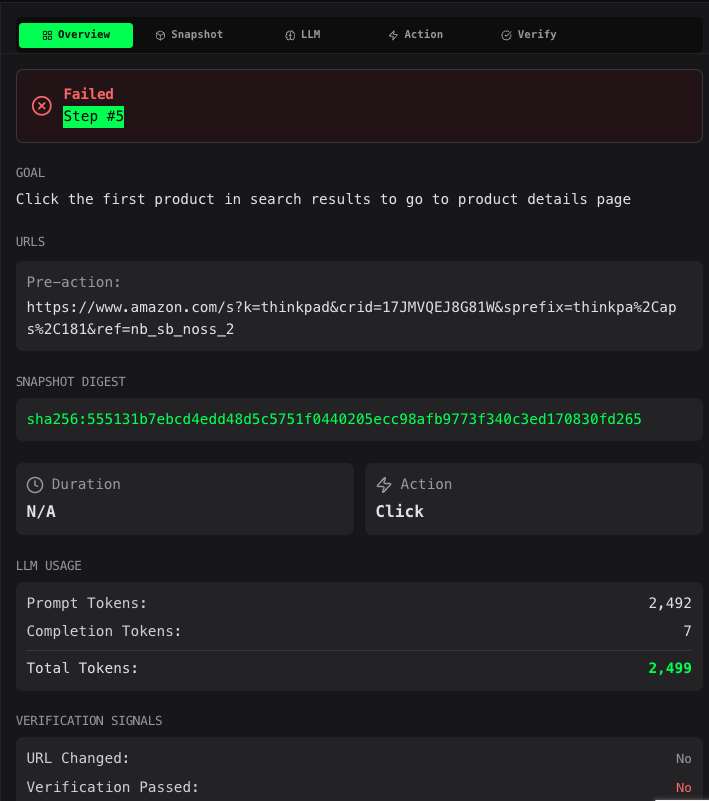
See the screenshot below for a step with failed assertion due to URL not being changed after a click event:
Sentience Studio provides a time line to walk through traces for each run, making it easy to debug and understand agent behavior.
Takeaways (first principles)
- Verification > intelligence for reliability. A modest model operating inside strict, deterministic tests will beat a stronger model operating without tests, because failures are detected and bounded.
- Vision is a fallback, not the control plane. Structure-first snapshots and assertions carry the flow; vision is used when necessary, not by default.
- Structure + verification makes small models viable. The executor is constrained to checkable actions; retries are bounded; failures produce artifacts.
- Local models become a rational default. Lower token usage enables better economics and improves privacy/deployment control.
- Larger planners help after verification is in place. They reduce plan drift and replan churn; they do not replace verification.
In Sentience, “verification” means explicit assertions over structured snapshots, with deterministic overrides when intent is unambiguous.
This is the Sentience approach: treat the browser as structured data, assert outcomes explicitly, and keep vision as a fallback. The result is a deterministic core that makes local LLMs practical without sacrificing reliability.
This approach is designed for teams that care about cost, data privacy/compliance, reproducibility, and debuggability - not for demo-only agents.